 n13eho's blog
n13eho's blogPensieve复现
仓库地址:GitHub - hongzimao/pensieve: Neural Adaptive Video Streaming with Pensieve (SIGCOMM '17)
1 配环境
Pensieve实验时间是在2017年,原环境是Ubuntu 16.04, Tensorflow v1.1.0, TFLearn v0.3.1 and Selenium v2.39.0,因此现在(2023)均达到这些要求需要和python及其他包的版本做好一番适配调整
1.1 ubuntu16.04虚拟机安装
轻车熟路,不赘述
1.2 Tensorflow v1.1.0
当我发现不用换成清华源也能装,我就没用清华的pip源了
首先安装py2.7的pip和依赖
|
|
然后直接安装tf
|
|
于是会遇到一个py版本的问题如下:
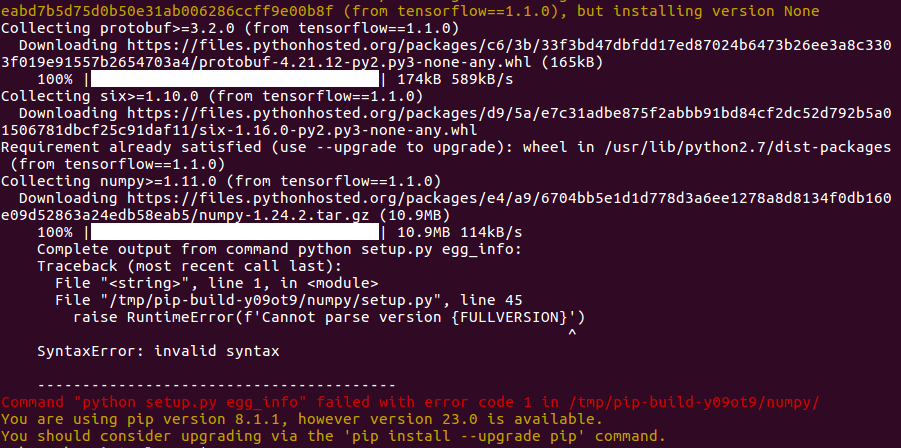
从连接看这边下载的是numpy的1.24.2版本,但是很多包可能从某个时候开始就不再支持python2了(比如这篇文章),所以需要手动降级,从官网上面找一个合适的版本提前装上

1.16.3是支持2.7的最后一代,那么就安装1.16.3
|
|
问题解决。但还有别的包如mock、MarkupSafe等等,解决方法都一样,在pypi网站上安装以前支持py2.7的版本即可。期间会碰到递归>=的需求,这个时候找到源头,都安装成最低版本的就行了
1.3 chrome and its driver
chrome: Download older versions of Google Chrome for Windows, Linux and Mac
chrome driver: ChromeDriver - WebDriver for Chrome - Downloads
我这里选择的chrome版本是104.0.5112.102,driver是104.0.5112.79。安装就一句话:
|
|
1.4 setup.py
我手动执行了这里面的包的安装,避免重复下载install,剩下的建立文件夹的部分保留,按README执行即可。(保留了这些内容:
|
|
2 cooked_trace 准备数据集
主要是下载数据集并将其转化为mahimahi的标准格式,否则会Died on std::runtime_error: Invalid integer。mahimahi的格式描述如下
Each line gives a timestamp in milliseconds (from the beginning of the trace) and represents an opportunity for one 1500-byte packet to be drained from the bottleneck queue and cross the link. If more than one MTU-sized packet can be transmitted in a particular millisecond, the same timestamp is repeated on multiple lines.
每一行都是一个从trace开始的时间戳,代表一个1500字节的包通过链路中的瓶颈队列的opportunity。
具体转化方法就直接用traces/文件夹下各个脚本跑,更改代码里面的输入输出路径即可。我用虚拟机跑的,速度比较慢
3 run_exp脚本调用链
3.1 run_all_traces.py
README里面一句话可以跑所有的脚本:python run_all_traces.py,这个py文件中就分别是写log,获取一个莫名其妙的ip地址,产生多条命令,最后再分别执行这些命令。
写完一句log之后,会用os.system(‘sudo sysctl -w net.ipv4.ip_forward=1’)来允许数据包转发,出于安全考虑
出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
注意这句话是临时生效的,所以每次都会被执行。
然后就是这句莫名其妙的ip,打印出来是111.199.68.11,不懂。。。
|
|
接着是调用另一个脚本,因为有不同的ABR算法,所以就有对应数量的指令:'python run_traces.py ' + TRACE_PATH + ' ' + ABR_ALGO + ' ' + str(PROCESS_ID) + ' ' + ip,可以看到都会从run_traces.py走,例如python run_traces.py ../cooked_traces/ BB 0 111.199.68.11
这个ip距作者说是为了获取自己的public ip,方便后面服务器web的访问吧,但是我在虚拟机中尝试多种和该ip建立连接的方法未果,我认为这个ip没有一点用
3.2 run_traces.py
该脚本从./cooked_traces中读取处理好的mahimahi格式的trace,对于每一个trace,执行命令
|
|
这边mm-delay是用mahimahi对网络环境进行模拟/仿真/构造,第二句则是用的下一个脚本run_video.py,也是使用到chrome的地方
python run_video.py 111.199.68.11 BB 320 0 test_fcc_trace_1171_http---www.yahoo.com_0 3
3.3 run_video.py
重点如下:
-
ip被作为生成的url,在用selnium启动chrome之后直接被调用,
driver.get(url)。此url就还是有问题,它怎么能代表对应的网页呢?怎么work的 通过自身作为web server,用apache提供服务,在setup.py中已经把对应的html文件复制到了/var/www/html中了 -
根据不同的abr算法启动了不同的server,BB的话是直接用的
../rl_server/simple_server.py。除了dashjs中的原生支持的算法,其余的决策过程都写在server的post响应方法中 That’s right. -
上一步的命令只穿了一个trace file的文件名过来,不是路径。除非又在外面套了一层根目录,否则不可能找得到,狗代码全是bug 请原谅我的无知,在稍微了解mahimahi的命令格式后我就知道了已经把trace传给mahimahi并且开始形成对应的网络环境了😅
mm-delay 40 mm-link 12mbps ../cooked_traces/test_fcc_trace_1171_http---www.yahoo.com_0 /usr/bin/python run_video.py 111.199.68.11 BB 320 0 test_fcc_trace_1171_http---www.yahoo.com_0 1
3.4 simple_server.py
simple_server和同目录下的其他server(mpc,rl等)并不是真正的服务端,而是执客户端。真正的客户端是localhost的apache服务开启的dashjs提供的,这些server负责不断向dashjs发出post请求,播放视频,做决策,写log。
除了mpc,rmpc,pensieve之外的bola,bb等abr算法,都直接运行在dashjs上面,每次客户端请求的url中的网址名称就请求了不同的html界面,那么是怎么做到区分内置算法的:html文件里就一个很简单的abr_id的不同就区分了不同的abr算法,这个肯定和其他的前端代码像交互的,对应的代码都使用grunt编译成了dash.all.min.js一起放进了服务器上(localhost),所以在使用这些算法的时候,本地的代码只用一个simple_server,负责log收集就好了。其余的算法,则会在post请求方法里面实现具体的决策逻辑,对于mpc等来说选择码率就是在这边代码里面选择的了。
因此如果要添加lumos就可以使用两种方法:1. 用python实现另一个lumos_server;2. 将lumos放到dashjs中,处于和bola平行的位置上。但注意这里是内置的,也就是要重新对dash.min.all.js用grunt重新编译,并且也得附上一份对应的myindex_lumos.html才行
还有一个我不明白的点是这个post和get的方法,他整个搜集log和做决策为什么是放在post里面的,模拟客户端不断请求的具体代码我并没有读很懂
4 run_exp跑不出来,遇到的问题
4.1 xvfb
error1:start error <EasyProcess cmd_param=[‘Xvfb’, ‘-help’] cmd=[‘Xvfb’, ‘-help’] oserror=[Errno 2] No such file or directory return_code=None stdout=“None” stderr=“None” timeout_happened=False>
搜了一下,要安装xvfb
|
|
4.2 mahimahi内部是否可通(?通了就有用了吗,这边通了也没用
然后验证一下mahimahi的ping和curl。查阅手册(man mahimahi)里面有格式
|
|
这一步是保证mahimahi本身网络连接没有问题,我看到有issue里有人提到这个
4.3 mahimahi下localhost拒绝访问,访问百度都不行🤯
error2:总是有个timeout的报错,总是执行到get(url)这里就无法继续,即便是将url换成百度也不行。但是单独执行后面的半句python run_video.py又是可以的。。。

单独执行一条语句,并且把ip地址改为localhost(本地是随时都开启那个apache服务的,可以直接访问

再次跑上上张图,就会出现拒绝访问的错误:unknown error: net::ERR_CONNECTION_REFUSED,在仓库的issue中也有同样的问题,作者的解释是:
The communication between inside and outside mahimahi shell is emulated. So you need to run the web server and chrome/selenium across shell.
我认识,但我不懂。梳理一下现在的问题就是:
-
这个error_conn 拒绝服务
-
不自动播放(只有一小段buffer被缓冲;log文件只有14行)
对于问题1,我所做出的无用尝试有:
-
直接从外面直接跑一个run_all_traces或许能行,事实证明还是不行,mahimahi一隔开就拒绝访问了
-
怀疑chrome和其driver版本太高所以换成了2020年左右的75.0.3770.8,结果仍然是拒绝访问
-
修改chrome的什么.desktop文件,在exce语句后添加–no-proxy-server之类的flag,是想禁用所有代理服务器,但也没用 4- 尝试充分理解run web server and chrome across shell的含义,未果
对于问题2,已解决,见4.4
4.4 视频不自动播放
通过查阅多则issue,解决方法是在run_video.py对chrome的设置处增添一句:
|
|

这里目前还是没有开启mahimhi,并且ip用的是locahost。这么跑可以生成想要的log,但还不够😈
4.5 mahimahi下的ERR_CONNECTION_REFUSED
4.4中的新添加的语句指向了一个新的abr相关的仓库park,这个py也是run_video.py,我翻看前面注意到了url的赋值的一句话
|
|
这里用的是MAHIMAHI_BASE,man手册里面也用这个代表了某个ip来ping过,可是我也验证过,拿这个代表出来的ip去访问html也是拒绝服务。。。
这个传媒大学的同学就是pensieve过来的,在pensieve那边没得到解决就在这里来问了,他的问题跟我的可以说是一模一样,作者的答复是:
`localhost' refers to the IP address of the local interface – and from inside a container, local really means “local” (still inside the container). This is not where your webserver is running.
You can use the $MAHIMAHI_BASE environment variable to refer to the local interface of the “main” container on your computer, outside the mahimahi container. This is probably what the webserver is listening to.
译:localhost指的是本地‘界面’的ip地址,那么如果是在一个内部的容器中,local的意思就是容器的local ip,这个ip地址是在容器里面的,但webserver不是在这个容器中(webserver在机器上,它前面没有加上mahimahi)运行的。
你可以用$MAHIMAHI_BASE这个环境变量去表示这个最主要的container的local 界面的ip,这个main container也就是机器了,是在mahimahi之外的那个container(主机也是一个container),这可能是webserver监听的地址(对于mahimahi来说)
所以我之前尝试在chrome中输入这个ip啥反应都没有,是不是因为我当时是在这个main container下面用这个ip其实是没有意义的,这个ip是mahimahi内部访问外部这个main用的地址??
ok,这句话换上了之后,从拒绝服务变为了timeout了。。。
现在可以区分:拒绝服务对应的ip,是mahimahi中能ping的通的,但是端口不一定开放,但是localhost这些也都是这个容器内部的localhost,并不是webserver真正的地方,所以这个拒绝服务就是纯纯错的;然而timeout,就是ping也ping不同的,是逻辑上容器内可以访问到外部webserver的地址,无奈它无法ping通。。。。苦恼
这是我今天上午惊人的发现:上下行的trace都换成那个简单的12mbps之后,它是能ping得通我main container的ip的!于是我又执行了wget去获取那个html界面,guess what,能下载得下来!这说明啥,说明是那个下行的trace file有问题,更换trace file!
更换过trace file之后,配合run_video.py中的url中直接使用$MAHIMAHI_BASE,整个就可以直接跑通了。
btw,mahimahi格式内容意思是,每一行对应一个时间戳,每一个时间戳就发一个大小为12Mb的数据包,因此一个带宽为12Mbps的trace的内容就是1,2,3,4;带宽为48Mbps就是1,1,1,1,2,2,2,2…
5 运行
开的2G内存的虚拟机一次性同时跑完所有的实验是不可能的。。。跑一晚上一个完整的log都出不来;耗时长,并且可能导致死机,可以像作者团队那样分几个机器来跑。这个虚拟机就开一个线程来跑,每次跑一个算法即可。
5.1 chunk fetch time为0的log
6 结果
7 添加一个新的ABR需要做的事情
前面提到,添加新的abr算法可以有两途径,区别是算法逻辑所在的位置:a)放在dashjs中;b)放在python的server中,卸载post方法里面。无论哪种都会需要dashjs层面上的改动,重新编译以及可能重新添加一个html文件。
经观察,凡用python这边rl_server做决策的ABR,他们对应的请求html文件都一样,也就是说新的abr算法也都用同一个html文件。所以这里选择这种方法,这样就无需再用grunt编译整个前端dashjs的部分了。